Blog Post by Daniel Holden, Animation Programmer at Ubisoft La Forge Research Lab
Breaking things is easy; fixing them is hard. This sad fact of life seems undeniable – that in almost all cases tearing things down seems to require just a fraction of the time, effort and concentration that goes into creating them in the first place.
And the same appears to be true of algorithms. It is much easier to write an algorithm that corrupts data, than it is to write an algorithm which fixes corrupted data. For example, writing an algorithm which replaces sections of an image with white rectangles is a far simpler process than writing an algorithm which attempts to fill in white holes in images with something meaningful.
There are two main reasons for this, each interesting in their own way.

The first, perhaps more obvious reason, is that when we corrupt something we remove information about what was originally there. Any algorithm we design must either have some kind of innate idea about how to fill in gaps, or needs to do clever things to predict what this information may be such as by looking at parts of the surrounding image.
The second, perhaps more interesting reason is that there are simply more algorithms that break things than that fix things. That sounds a bit odd, but consider it like this: if we have a corrupted image which we want to fix, there may be only a single correct way to fix that image, and so the algorithm we would need to produce this very particular result is extremely specific. On the other hand, if all we need to do is corrupt the image more, there are an almost infinite number of ways we could do that. If we were to pick an algorithm at random to apply to the image, the likelihood is it wouldn’t be the one which would fix it, but that it would almost certainly be an algorithm which would break it even more. To put it briefly – coming up with algorithms which break things is easy simply because there are so many of them – while coming up with algorithms which fix things is difficult because they are extremely rare.
So is that it? Is fixing things just fundamentally a difficult task no matter how we look at it? It feels like that is the case, but there is actually a way to look at the problem which puts fixing stuff and breaking stuff on a much more equal footing, but it requires re-thinking a little bit about how we build algorithms.

Most of the time we design algorithms by hand – explicitly writing down the individual steps we want the computer to perform, but there is another way to build algorithms in computer science which works differently. We can also build algorithms from data – by providing many examples of inputs to the algorithm and corresponding desired outputs. This is called Machine Learning and the way it works is that we take hundreds, thousands, or even millions of examples of inputs to the algorithm and the corresponding desired outputs we wish the algorithm to produce, and we give them to a more generic kind of algorithm, which uses all this data to adjust some kind of internal settings until it matches the behavior we are training it to perform.

And here is the thing – in this setup, training an algorithm to corrupt data is not really any different to training an algorithm to fix data, the only difference is in what order we give the inputs and outputs – do we tell it to take in good data as input and produce corrupt data as output, or do we tell it to take corrupt data as input and produce good data as output? Everything else remains exactly the same.
Additionally, since corruption is so easy to perform it is also extremely easy to prepare the data for an algorithm built like this. All we need is a large database of good quality data, and we can very easily produce corresponding corrupted data simply by running our simple corruption algorithm. The fact that we can easily corrupt data actually helps us in this case – it is exactly what provides us with the data required to train our algorithm in the first place.
This idea has been around in the Machine Learning community for a long time, but it is only recently that we had powerful enough Machine Learning algorithms to really use it effectively. Since then it has been used to produce some incredible results, and in the last few years, things that were previously thought close to impossible such as Image Inpainting, automatic colorization of photos, and CSI style super resolution are now fairly standard ways of applying this technique.
In my most recent research called “Robust Solving of Optical Motion Capture Data by Denoising” I applied this very same idea to the task of automatically fixing broken motion capture data.
Raw optical motion capture data often contains errors including markers disappearing from sight, or the system confusing one marker with another. At Ubisoft we process a lot of this kind of motion capture data, and right now, the cleaning, processing, and quality checking of this motion capture data can often become a bottleneck in the pipeline when the capture studio is very busy because generally these errors need to be fixed by hand.
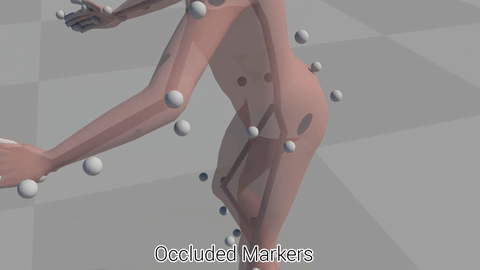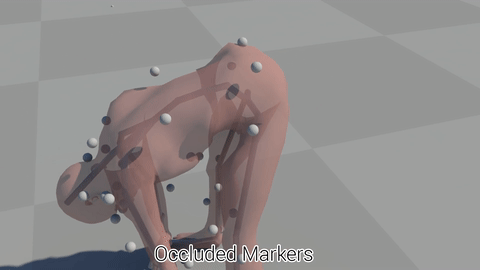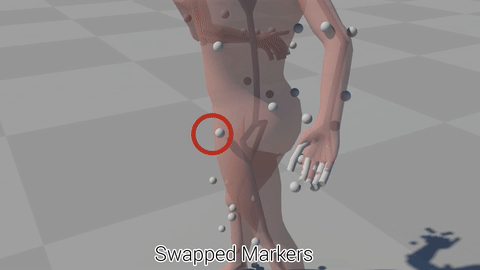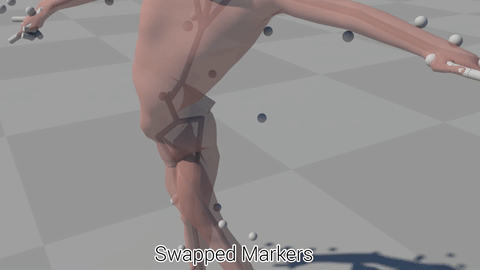
But if we start thinking in terms of Machine Learning, then the fact that so much motion capture data is being processed at Ubisoft is actually a huge win, because it means we have a massive database of cleaned motion capture data which we might be able to use to train machine learning algorithms.
And in my most recent research this is exactly what I did – I took this huge database of motion capture data and built a system which could dynamically corrupt it using a specifically designed corruption function which I designed to emulate the same kind of errors that could appear in motion capture data. I then used this database of motion data, along with the corruption function to train a Machine Learning algorithm to do the exact opposite – to take as input the corrupted data and to produce as output the original clean data.
Once trained, this algorithm could be used on any new data that was seen, and in almost all cases it produced nicely cleaned up results.

In fact, in this research I took it one step further, because after motion capture data is cleaned there is a second step (called solving) where the character skeleton is extracted. This process is also reversible (that is – we know an algorithm which can reconstruct the marker locations given the skeleton and a particular body shape) which means we can extend the algorithm to correct more of the pipeline – as from a character skeleton we could easily produce a set of corrupted marker positions.
So the final machine learning algorithm is now trained to map directly from raw, unclean marker data, corrupted by my artificial noise function, back to the joints of the character which produced the data – free of any errors. It means all you really require to make use of this algorithm is a large database of skeletal animation data, some of which are freely available online (E.G. the CMU motion capture database).
If you want all the details please watch the supplementary video or read the paper, but for me this work was most interesting in demonstrating of one of the more fascinating and surprising results to come out of Machine Learning – which is that if we know well how to break things, often fixing them can be made just as easy.

To read more blog posts from Daniel Holden, take a look at his website.

