
Image stéréotypée d’une ébauche d’image clé; l’animateur doit dessiner des images intermédiaires en fonction du chronogramme à droite. Notre système automatise la tâche d’interpolation. (source)
Chez Ubisoft, nous travaillons sans relâche afin de créer des mondes toujours plus vrais que nature. Cette quête de réalisme a une incidence sur de nombreux aspects d’un jeu vidéo, notamment sur les animations des personnages. Pour rendre les jeux vidéo plus immersifs et veiller à ce que les joueurs puissent s’identifier aux personnages, proposer des animations naturelles est indispensable. Mais créer des animations de haute qualité nécessite énormément de ressources. Dans cet article, nous adoptons une approche guidée par les données qui s’appuie sur des réseaux neuronaux antagonistes récurrents pour automatiser certaines étapes du flux des tâches de création d’animations. Le processus tire parti de données de capture de mouvement (MOCAP) de grande qualité pour générer des transitions réalistes entre des images clés temporelles distinctes. (Article au format PDF)
Un exemple canonique de transitions recherchées dans un jeu vidéo. Nous possédons deux images clés uniques (posture accroupie et posture de course) qui ont été dupliquées afin de créer une séquence en trois segments. Toutes les images clés consécutives sont espacées d’une seconde, correspondant à 30 images. L’animation est générée par notre modèle.
PROCESSUS HABITUELS
Capture de mouvement
L’industrie cinématographique et le secteur des jeux vidéo ont recours aux technologies de MOCAP (pour « Motion Capture », capture de mouvement) depuis maintenant plusieurs années afin de créer des animations réalistes, la MOCAP permettant en effet de restituer de manière extrêmement fidèle les mouvements humains dans les animations. Toutefois, les séances de MOCAP et le post-traitement indispensable des séquences nécessitent beaucoup de ressources, et tout est mis en œuvre pour éviter d’avoir à organiser des séances de capture supplémentaires. Toujours dans un souci d’épargne des ressources, il n’est pas rare que les équipes étudient la possibilité de réutiliser des séquences de MOCAP existantes dans le cadre de l’élaboration de nouvelles animations avant d’organiser de nouvelles séances de capture de mouvement. Toutefois, trouver les séquences de MOCAP adaptées à des besoins spécifiques n’est pas chose aisée, et modifier une séquence existante afin de répondre aux contraintes d’une nouvelle animation peut être chronophage.
Animation par image clé
L’animation par image clé, également appelée « animation à la main », est une autre manière de produire des mouvements artificiels qui a longtemps constitué la technique d’élaboration d’animations par excellence. Là encore, le processus peut s’avérer long et fastidieux afin d’obtenir un rendu d’animations 3D réaliste digne d’un jeu AAA. De fait, étant donné que les outils d’animation actuels sont dépourvus d’une fonctionnalité d’interpolation de qualité pour traiter des images-clé éloignées dans le temps, les animateurs passent un temps non négligeable à créer un grand nombre d’images clés temporellement denses. Notre système a pour but d’accélérer le processus en faisant en sorte que les images clés distinctes soient automatiquement reliées entre elles au moyen d’une animation naturelle rendue possible grâce aux données de MOCAP. Cela s’apparente à la tâche d’interpolation des flux des tâches d’animation traditionnels, qui consiste pour l’animateur inbetweener à créer le mouvement reliant des images clés fournies par un artiste ou un animateur clé.
INTERPOLATION AUTOMATIQUE DU MOUVEMENT
Vue d’ensemble
Notre système est conçu pour utiliser, en tant qu’inputs, jusqu’à 10 images initiales comme contexte passé (past context), ainsi qu’une image clé cible (target frame). Il se charge ensuite de produire le nombre d’images de transition souhaité afin de relier le contexte passé à la cible. Dans le cas d’une génération de plusieurs transitions à partir de plusieurs images clés, le modèle est simplement appliqué de manière successive, et se sert des dernières images générées comme contexte passé pour la séquence suivante.

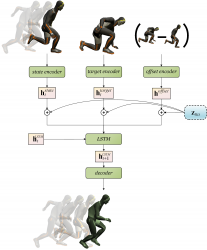
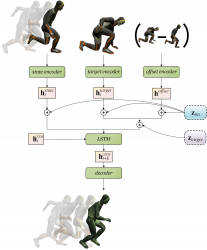
Un aperçu visuel de notre système. De façon générale, notre système accepte jusqu’à 10 images initiales comme contexte passé ainsi qu’une image clé cible, afin de produire la transition manquante entre le contexte passé et la cible. Plus précisément, le modèle récurrent autorégressif produit une seule image à la fois jusqu’à ce que toutes les images manquantes aient été générées.
Architecture

Notre architecture repose sur les réseaux de transition récurrents (RTN, pour « Recurrent Transition Networks ») que nous avons présentés lors de la conférence SIGGRAPH Asia 2018.
Il utilise trois encodeurs qui sont des Perceptrons multicouches (MLP – Multi-Layer Perceptron).
- L’encodeur d’état prend en entrée la posture actuelle du personnage, exprimée par la concaténation de l’orientation et vitesse du pelvis, les rotations locales des articulations ainsi que les valeurs binaires de contacts de pieds. Toutes les rotations sont exprimées en quaternion.
- L’encodeur de cible utilise en entrée la posture cible, exprimée sous la forme d’une concaténation de l’orientation du pelvis et rotations locales des articulations en quaternions.
- L’encodeur d’écart utilise en entrée l’écart actuel entre l’image clé cible et la posture actuelle, exprimée sous la forme d’une concaténation de différences linéaires entre les positions et les orientations du pelvis, et entre les quaternions locaux.
Dans l’architecture RTN d’origine, les représentations obtenues pour chacune de ces entrées sont directement transmis à une couche récurrente Long-Short-Term-Memory (LSTM), qui est chargée de modéliser les dynamiques temporelles de l’animation.
Le résultat de la couche LSTM est ensuite transmis au décodeur, un autre Percpetron Multicouche, qui produira la posture et les contacts prévus du personnage afin de calculer les différentes fonctions de perte.
Nous avons une perte angulaire calculée sur les quaternions du pelvis et quaternions locaux des autres articulations , une perte de position calculée sur la position globale de chaque articulation récupérée par le biais de cinématique directe (voir Quaternet), une perte du contact du pied en fonction de la prévision des contacts, et une perte antagoniste.
La perte antagoniste est obtenue en entraînant deux réseaux MLP discriminateurs (aussi appelés Critiques), qui sont eux-mêmes entraînés pour différencier les segments de mouvement réels de ceux générés. Nous utilisons des critiques coulissantes qui classifient plusieurs segments de longueur fixe pour chaque transition générée. Cshort-term utilise les segments de deux images en tant qu’input, et Clong-term ceux de 10 images. Les critiques sont entraînés au moyen de la formule Least-Square GAN, et la moyenne des scores de tous les segments est calculée pour obtenir la perte finale.
ROBUSTESSE AU MOYEN DE MODIFICATEURS LATENTS ADDITIFS
Code de Délai Restant 
Notre premier modificateur latent est emprunté des réseaux transformateurs, qui sont couramment utilisés dans le traitement automatique du langage naturel (TALN). Ces modèles basés sur l’attention n’utilisent aucune couche récurrente lors du traitement de phrases, et ont besoin d’une méthode afin de connaître le classement des séquences de mots. Ils utilisent un vecteur continu dense appelé « code positionnel » qui évolue progressivement avec la position du mot. Chaque dimension de ce vecteur suit un signal sinusoïdal avec un décalage de fréquence ou de phase différent, rendant ainsi le vecteur unique pour chaque position.
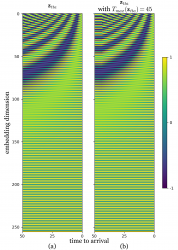
De notre côté, nous utilisons la même formule mathématique des codes positionnels, mais qui s’appuie sur un délai restant plutôt que sur une position de jeton. Ce délai restant représente le nombre de trames devant encore être générées avant d’atteindre l’image clé cible. Cela déplace donc les représentations latentes des entrées dans différentes régions de l’espace latent en fonction du délai restant. Passé un certain nombre de trames de transition, Tmax(ztta), nous fixons nos codes de délai restants afin qu’ils restent constants. Cela permet au modèle de généraliser vers des segments plus longs que ceux observés pendant l’entraînement, au cours desquels les codes de délais pouvaient autrement amener les représentations des entrées dans une région inconnue de l’espace latent. La figure ci-dessus représente de manière visuelle ztta avec et sans Tmax(ztta).
En appliquant les codes de délai restant, nous permettons au réseau neuronal de traiter les différentes longueurs de transitions pour un ensemble d’images clés donné. Cette flexibilité accrue est nécessaire pour qu’un tel système puisse être utilisé par des animateurs. Les effets peuvent être vus ci-dessous, où seul l’espacement temporel des images clés varie.
Bruit de cible programmé 
Afin d’améliorer la robustesse des modifications apportées aux images clés et de permettre l’échantillonnage de transitions avec notre réseau, nous nous servons d’un deuxième type de modificateur latent additif appelé « bruit de cible programmé ». Ce vecteur ztarget = z * σtarget est un vecteur aléatoire normal standard z mis à l’échelle par un paramètre contrôle de stochasticité σtarget et échantillonné une fois par transition. Il est uniquement appliqué aux représentations latentes de la cible et de l’écart courant. Nous mettons ztarget à l’échelle par un scalaire λtarget qui diminue de manière linéaire pendant la transition et atteint zéro cinq trames avant la cible. Cela a pour effet de déformer la cible et l’écart perçus au début de la transition, et de supprimer progressivement le bruit à mesure que l’animation se poursuit. Étant donné que nous déplaçons les représentations de cible et d’écart, ce bruit a une incidence directe sur la transition générée. Il permet ainsi aux animateurs de contrôler facilement le niveau de stochasticité du modèle en spécifiant la valeur de σtarget avant de lancer la génération. Utiliser σtarget=0 rend le système déterministe. Nous montrons les effets ci-dessous, où les trois variations par segments sont échantillonnées avec σtarget = 0.5 :
RÉSULTATS COMPLÉMENTAIRES
Pour en savoir plus et consulter d’autres résultats quantitatifs, consultez notre article Robust Motion In-Betweening (Interpolation robuste de mouvement) publié à l’occasion de la conférence SIGGRAPH 2020. La vidéo annexe présente d’autres résultats et limitations qualitatifs, ainsi qu’un exemple du flux de travail d’un animateur utilisant notre système dans le module personnalisé d’un outil de création d’animations.
REMARQUES FINALES
Cet ouvrage représente une avancée majeure, qui permet de faire le lien entre la capture de mouvement et les techniques d’animation à la main en intégrant la qualité du MOCAP au flux des tâches d’animation par image clé pour repousser les limites de l’animation 3D. Grâce à notre système, nous dépendons moins des séances de capture coûteuses et diminuons la charge de travail des animateurs en améliorant les techniques d’interpolation des logiciels courants. Bien que nous ayons déjà commencé à appliquer ce système dans le cadre de la production de jeux vidéo, il reste de nombreuses pistes à explorer afin de relever les défis restants que présentent les cas extrêmes.
Autres recherches dans le domaine de l’animation chez Ubisoft La Forge
- Nous avons récemment publié l’ensemble de données d’animation LaFAN1 d’Ubisoft La Forge, qui a servi à alimenter nos modèles dans le cadre de l’élaboration de cet article.
- L’équipe d’animateurs d’Ubisoft La Forge a également publié l’article Introduction à la sélection apprise de mouvement dans le cadre de la conférence SIGGRAPH 2020, dans lequel elle apporte des solutions aux problèmes d’extensibilité de la mémoire de la correspondance de mouvement traditionnelle et utilise une partie de l’ensemble de données LaFAN1.
BibTex
@article{harvey2020robust,
author = {Félix G. Harvey and Mike Yurick and Derek Nowrouzezahrai and Christopher Pal},
title = {Robust Motion In-Betweening},
booktitle = {ACM Transactions on Graphics (Proceedings of ACM SIGGRAPH)},
publisher = {ACM},
volume = {39},
number = {4},
year = {2020}
}

